


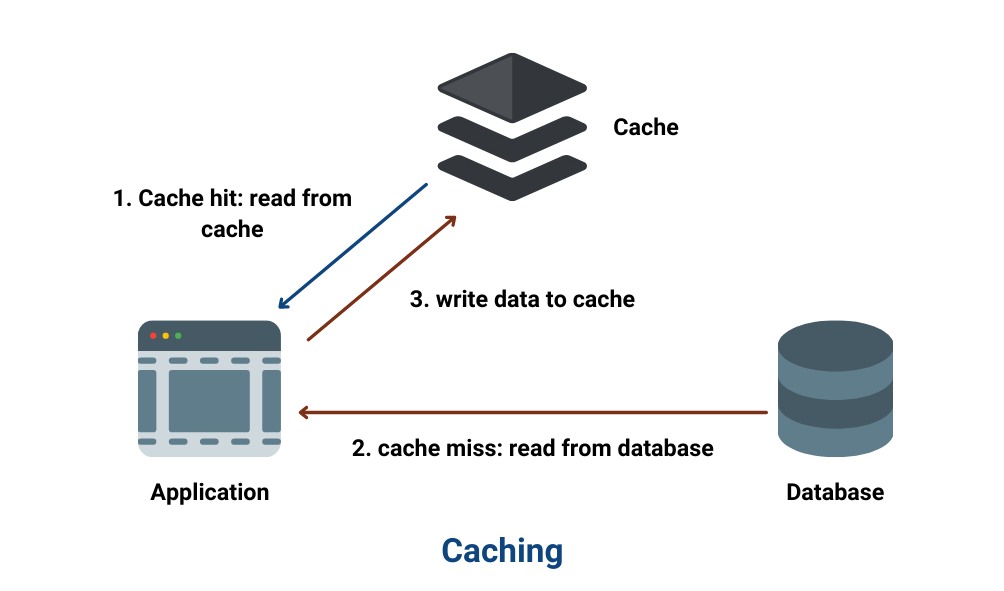
Caching - System Design Concept
In this blog, we will learn about Caching, an important fundamental concept in a system’s design. Have you ever experienced that when you open a…

Amazon, Ola Cabs
Have you ever thought of any such service that could make our life easier by allowing us to store data over the internet and simultaneously allow others to access the same data? If it is so, then this is the perfect blog for you. Here, in this blog, we’ll be discussing the PasteBin System. Here, the aim is to design a highly scalable service that could allow users to paste various content (images, text, etc.) over the internet and allow others to access the pasted content. So let’s look at the formal definition of Pastebin.
Pastebin is a type of online content hosting service where users can store and share content in the form of text or images over the internet by generating a unique URL so that anyone can access the contents via that URL. The user who created it can also update the content if he/she is logged in. So without much delay, let’s dive deep into designing such a scalable service from scratch.
Requirements analysis is a critical process that enables the success of a system. Requirements are generally split into two types: Functional and Non-Functional Requirements.
Functional requirements are the essential requirements that the end-user demands as necessary facilities that the system should offer. For PasteBin, the functional requirements are:
Non-Functional Requirements are the quality constraints that the system must satisfy according to the project contract. For PasteBin, the non-functional requirements are:
As we know, what are our essential requirements, so it’s time to estimate the service’s capacity.
It is necessary to know the approximate traffic to the service to be scaled and designed accordingly. Since this service would be read-heavy, it is better to consider read to write the ratio as 10:1. Assume we have 10M users, and each user contributes one write a request on average per month. So we have -
-> 10 Million write requests per month
-> 100 Million read requests per month (10X write request)
-> Hence the total number of writing request in 10 years
= 10M*12(months/year)*10(years)= 1.2 Billion write requests
Let the maximum size per paste be 10MB.
-> Amount of paste size per month
= 10 M*10MB = 100 TB paste/month
-> Amount of paste content in one year
= 100TB*12 = 1200TB or 1.2PB paste/year
Assume our service runs for 10 years,
then total data accumulated = 1200TB * 10 years = 12 PB

We have two high-level working API for this service: one for writing the content and the other one for dealing with reading requests. We can use either SOAP or REST architecture to implement the system.
write( key, content, expiry_date)
Parameters: key, content, expiry_data
Return Value: API should return a short URL to access the content or otherwise, in case of invalid input, it should return an error code
The user enters the content and gets the randomly generated URL. This works in the described way
-> The Client sends a create paste request to the Web Server,
which in turn the request forwards to the Write API server.
-> The Write API server does the following:
-> Generates a unique URL
-> Saves to the SQL Database pastes table
-> Saves the content to the Object Store and returns the URL
read (short_url)
Parameters: short_url
Return Value: API should return the original paste content or an invalid error code if the URL is incorrect.
The user enters a pasted URL and views the content. This works in the following way:
-> The Client sends a get paste request to the Web Server,
which in turn forwards the request to the Read API server.
-> The Read API server does the following:
-> Checks for the generated URL in the SQL Database
-> Fetch the paste contents from the Object Store if the URL is in the SQL Database
-> Otherwise, return an error message for the user
Besides these essential services, we also have two more APIs responsible for Real-Time analytics(out of scope) and the deletion of expiration content.
delete (api_key, URL)
Parameters: api_key, URL
Return Value: Boolean Value indicating success and failure.
The key component of this service relies on generating short URLs and storing the content. Let’s discuss these in details:
Every time whenever a user makes a paste, the service needs to generate a unique new short URL. We can use BASE64 for encoding the URL as all the characters of BASE64 are URL-safe characters(characters allowed [A-Z][a-z][0–9],’+’,’/’).
Since we have 12B write requests we can easily do with a URL of length 6 but by considering to make the system highly scalable we should choose a URL of length 7.
To generate the unique URL, we could take the MD5 hash of the user’s ipaddress + timestamps. We have various choices like ipaddress+timestamp or ip_address + content, but as content would be very large to handle hence we use the other. Alternatively, we could also take the MD5 hash of randomly generated data
Now when we encode the MD5 result to Base64 encoding the resultant string will be 22 characters long.
Base64 encoding will use 6 bits to represent each character,
MD5 -> Base64 give (128/6) ~ 22 character output.
Hence, we could use:

For choosing the short URL, first, we can choose the first 7 characters of the resulting Base64 encoding.
The drawback of this algorithm
The primary issue with this algorithm is that the generated URL can be repeated. Hence to overcome this, KGS(Key Generating Service) comes to rescue us. KGS algorithm will ensure that all the keys inserted into key-DB are unique and hence we don’t have to worry about duplication or collisions.
We need to store both the content and the short URL. The average size of each content is 10MB. As calculated above, for our service to be available for ten years, we have to accommodate a massive amount of data, i.e., 12 PB, which is too much to be stored in any database. Hence, we have to use Object Storage Service, such as Amazon S3, for storing the content and a normal relational database for storing URLs.
The structure of the database is described here:
User Data
1. User ID: A unique user id for each user
2. Name: User’s Name
3. Email: The email id of the user
4. Password: Password of the user
5. Creation Date: The date on which the content was shared
Content Data
1. User ID: A unique user id for each user
2. Short URL: A unique short URL consisting of 7 char
3. Paste Path: The URL path of the S3 Bucket
4. Expiration Date: Time after which content expires
5. Last Accessed: Last time when content was accessed
The User ID is used as a Primary Key in the above structure.

For storing the paste content (URL), we have two choices to choose from. We can either go with Relational Database like MySQL, or we can go with a NoSQL database. As we want fast read and write speed, but we don’t need lots of relationships among data. Hence NoSQL Databases are the optimal choice for our system.
Relational Databases are very efficient when there are many dependencies, and when we have lots of complex queries, they are too slow. However, NoSQL databases are very poor at handling the relationship queries, but they are faster.
This is the most critical aspect of business requirements. The service should be highly scalable, and at the same time, it should be reliable, available, and fast enough for a better user experience. We need to scale our database, have more servers to handle more requests, and be fast enough.
It will be expensive, and the service will be prolonged and become more prone to failure if we use a single database to store the data. Hence we need to partition it into several machines or nodes to store information about billions of URLs.
For database partitioning, we can use the Consistent Hashing technique. The hash function will be used to distribute the URLs into different partitions. We need to decide the number of shards to make, and then we can choose an appropriate hash function that random number represents the partition/shard number.
We have ten times more read operation as compared to write operation. Hence to speed up our service, we need to use caching. Cashing is a way to speed up the reading process. The URLs which are accessed quite frequently should be stored in the cache for faster access. For example, if any URL appears on any social networking website’s trending page, many people will likely visit the URL. Hence we can store its content in our cache to avoid any delay. We can use services like Memcached or Redis for this purpose.
Various possibilities need to be kept in mind while designing the cache. Some of them are:
We can use Distributed Cache to incorporate all the above possibilities.
The designed system might be prone to network bandwidth bottlenecks and a single point of failure. To overcome this problem, we use Load Balancing. There might be instances when many requests went to a single server, resulting in the service’s failure. There are many algorithms available to distribute the load among servers, but here in this system, we will use the Least Bandwidth Method. This algorithm will divert the incoming request to the server serving the least amount of traffic.
Along with balancing the load, we need to replicate all the databases and servers to avoid failure. In case of any discrepancy, the service should never go down and should remain highly consistent.
PasteBin System is a complex and highly scalable service to design. In this blog, we have covered the fundamental concepts necessary for building such a service. We hope you like the content. Please do share your views.
In this blog, we will learn about Caching, an important fundamental concept in a system’s design. Have you ever experienced that when you open a…
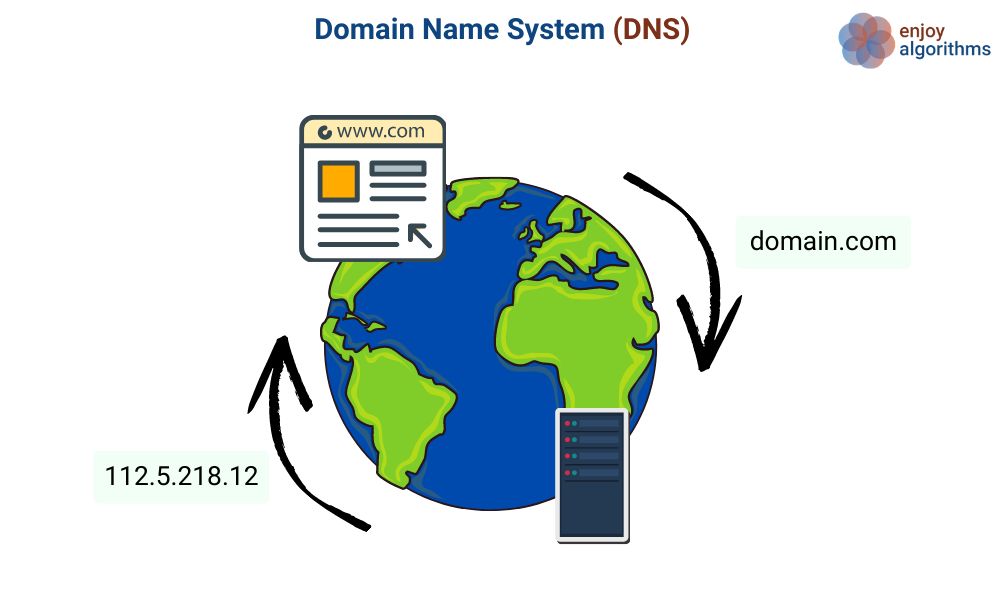
Thirty years ago, when the Internet was still in its infancy when you wanted to visit a website you had to know the IP address of that site. That’s…
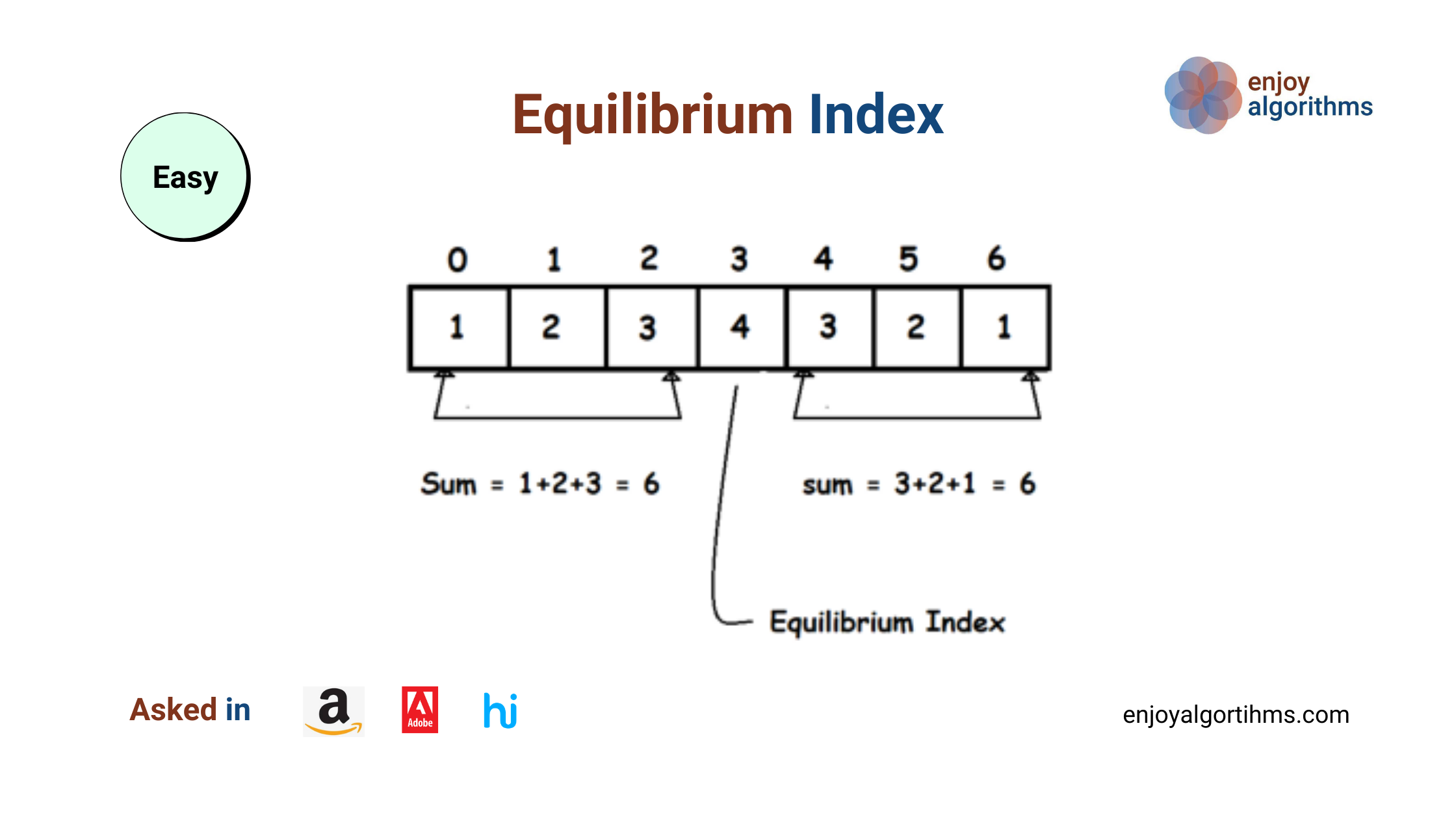
Difficulty Level Easy Asked In Amazon, Adobe, Hike Three solutions Discussed Brute force approach — Using two nested loops Using extra space — Using…
Subscribe to get free weekly content on DSA, Machine Learning and System Design. Content will be delivered every Monday.
