



Design PasteBin - System Design Interview Question
Asked In Amazon, Ola Cabs Key benefits after reading this Blog Have you ever thought of any such service that could make our life easier by allowing…
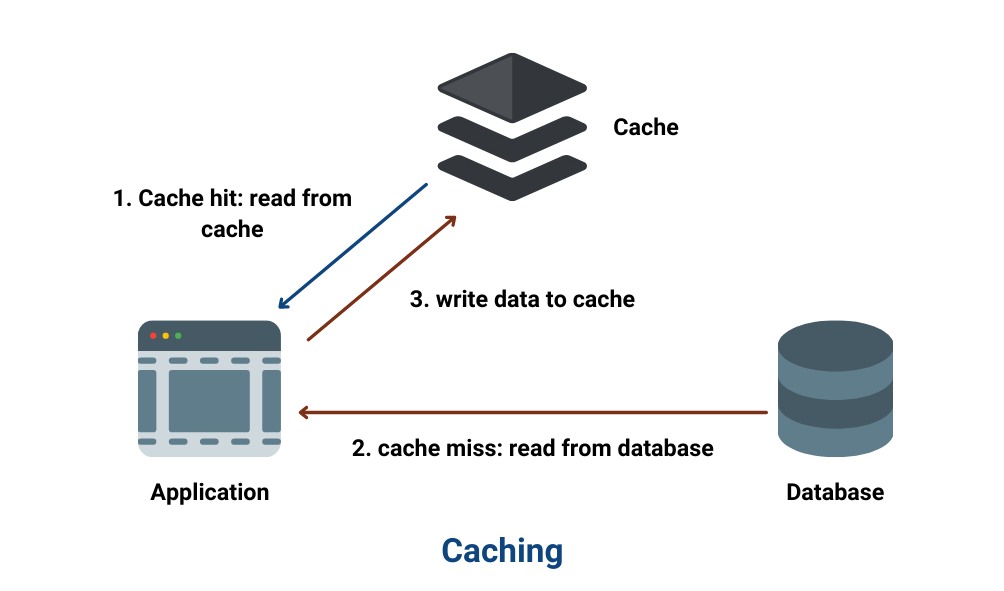
In this blog, we will learn about Caching, an important fundamental concept in a system’s design. Have you ever experienced that when you open a website the first time, it takes more time than usual, but when you open the same website again, it takes no time to load? Do you know why this happens? Let’s find out!

Caching is the process of storing the results of a request at a different location than the original or a temporary storage location so that we can avoid redoing the same operations. Basically, the cache is temporary storage for files and data such that it’s faster to access this data from this new location.
Let us take an example of a librarian to understand the basic idea behind the cache system. Let us imagine a library with 1000s of books and a librarian behind the desk whose responsibility is to get you the desired book from the library store. First, let’s start with a librarian without a cache.
The day starts, and the first customer arrives. He asks for a book; let’s say Book A. The librarian goes to the storeroom, fetches the book, returns it to the desk, and issues the book to the customer. After some days, the customer returns the book, and the librarian keeps the book back to its place and returns to her desk to wait for another customer. Now, the next customer arrives, and he asks for the same Book A. The librarian again has to go to the same place and fetch the book and give it to the customer. In this system, the librarian has to visit the store every time a customer arrives — even to get the book that is demanded frequently.

Now, let’s put the librarian on her desk a bag that can store 15 books (like a 15 book cache). In this bag, the librarian can keep the books that customers have recently returned. Now, the first customer arrives and requests Book A, and the librarian has to go to the storeroom and give it to the client. Later, the customer returns the book, and instead of going to the storeroom to return the book, the librarian keeps it in her bag. Another customer arrives; he asks for the same Book A. This time the librarian checks if she has the book in her bag, and he finds it! This time the librarian doe not have to make a round trip to the storeroom, and hence the customer is served more efficiently.
Let’s implement a simple caching system:
First, we will create a simple server and a database. We will use the database to get the HTML page and the server to host the page locally. We will create two end-points, one that uses the cache and the other that does not.

If we look in the browser on the server with the endpoint having no-cache, it will take 3 seconds to load (since we used setTimeout to load the page with no cache in 3 seconds). If you refresh this page again, it will again take 3 seconds to load the page because every time we refresh the page, it goes to the database to fetch it.
Now, in the end-point, which uses caching, the first time we go to the endpoint with-cache, it takes 3 seconds to load the page since the cache is empty and has to go to the database to fetch the data. But, when we refresh the page, it loads instantly. As soon as we loaded the page the first time, we cached the results for future requests.
We need to delete existing items for new resources when the cache is complete. In fact, it is just one of the most popular methods to delete the least recently used object. The solution is to optimize the probability in the cache that the requesting resource exists.
We can cache the data directly in the Application Layer. Every time a request is made to the service, it will return local, cached data quickly if it exists. If it is not in the cache, it will query the data from the database.
In Global Caches, the same single cache space is used for all the nodes. Each of the application nodes queries the cache in the same way as a local one would be.
The cache is usually broken up using a consistent hashing algorithm, and each of its nodes owns part of the cached data. If a requesting node is searching for a certain piece of data, it can easily use the hashing function to locate information from the distributed cache to decide if the data is available.

When our pages serve huge amounts of static media, this is the best option. Suppose that the framework we are developing is not yet big enough to have a CDN of its own! “Using a lightweight HTTP server like apache, we can serve static media from a different subdomain such as “blog.enjoyalgorithms.com” and cut the DNS from your servers to a CDN layer.
Client-side caching duplicates the data of previously requested files directly within browser applications or other clients (such as intermediate network caches).
ISP caching works in much the same way as browser caching. Once you have visited a website, your ISP may cache those pages so that they appear to load faster the next time you visit them. The main problem with this is that, unlike your browser cache, you can not delete these temporary files; instead, you have to wait until your ISP's cache expires and requests fresh copies of the files.
It should be invalidated in the cache if the data is changed in the database; if not, this may trigger inconsistent application actions. There are primarily three kinds of systems for caching:

Asked In Amazon, Ola Cabs Key benefits after reading this Blog Have you ever thought of any such service that could make our life easier by allowing…
Thirty years ago, when the Internet was still in its infancy when you wanted to visit a website you had to know the IP address of that site. That’s…

The system design interview is an open-ended conversation. As a candidate, we are expected to lead it along with a discussion with the interviewer…
Subscribe to get free weekly content on DSA, Machine Learning and System Design. Content will be delivered every Monday.
