

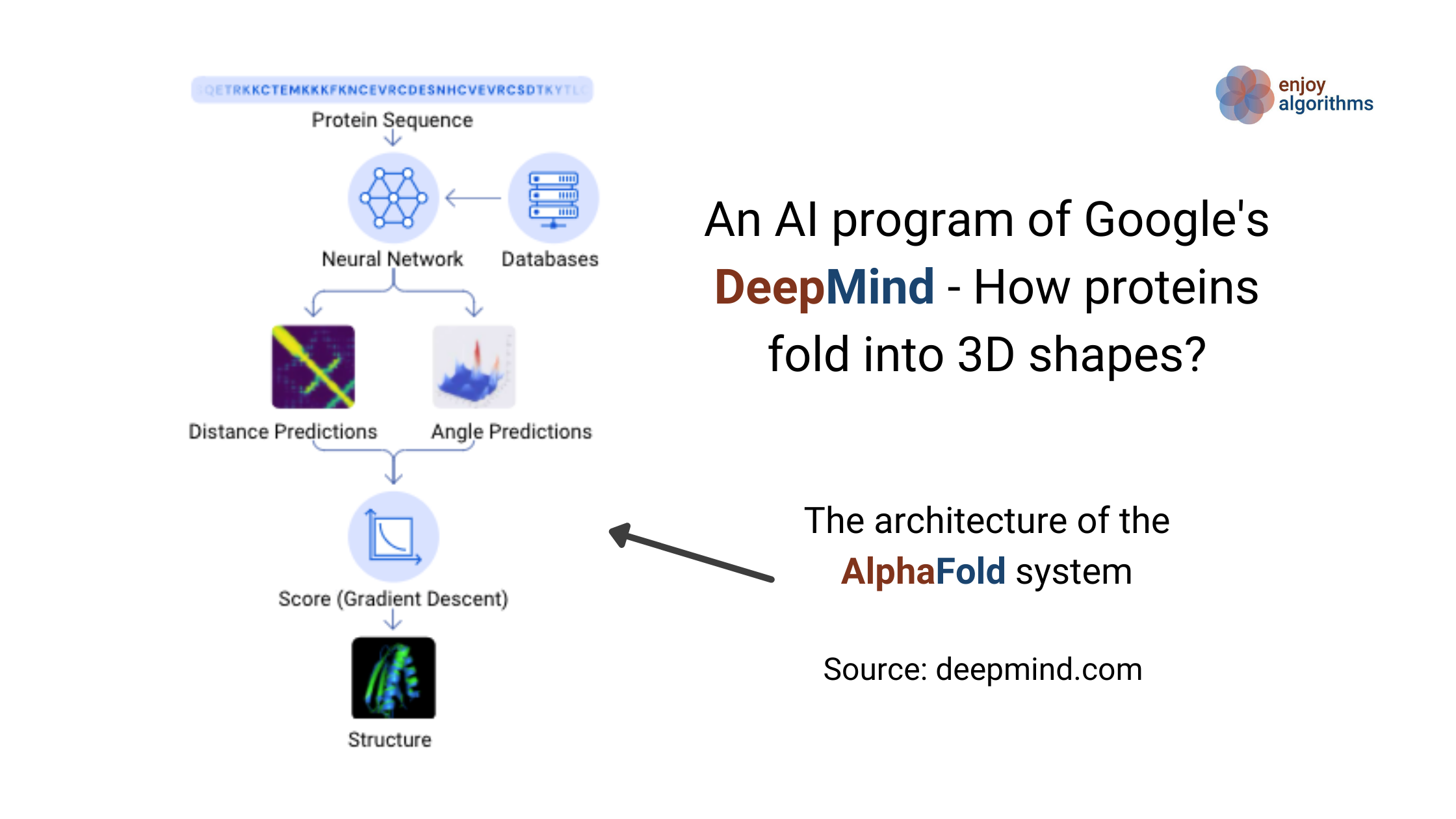
An AI program of Google's DeepMind - How proteins fold into 3D shapes?
AlphaFold, an AI program of Google's DeepMind, solved the mystery of "How proteins fold into 3D shapes?". It was a mystery question for the past 5…

In the new era of technical advancement, electronic mails (e-mails) have gathered significant users for professional, commercial, and personal communications. In 2019, on average, every person was receiving 130 emails each day, and overall, 296 Billion emails have been sent in that year.
Because of the high demand and huge user base, there is an upsurge in unwanted emails, also known as spam emails. There were times when more than 50% of the total emails were spam emails. Even in the current date, people lose millions of dollars to frauds every day.
But, in the figure shown below, it can be observed that the quantity of such emails has decreased significantly after 2016 because of the evolution of the software that can detect these spam emails and can filter them out.

Percentage of emails marked as Spam (Source: Statista)
Many several techniques are present in the market to detect spam e-mails. If we want to classify broadly, there are 5 different techniques based on which algorithms decide whether any mail is spam or not.
Algorithms analyze words, the occurrence of words, and the distribution of words and phrases inside the content of e-mails and segregate them into spam non-spam categories.
Algorithms trained on well-annotated spam/non-spam marked emails try to classify the incoming mails into two categories.
Algorithms use pre-defined rules in the form of a regular expression to give a score to the messages present in the e-mails. Based on the scores generated, they segregate emails into spam non-spam categories.
Algorithms extract the incoming mails' features and create a multi-dimensional space vector and draw points for every new instance. Based on the KNN algorithm, these new points get assigned to the closest class of spam and non-spam.
Algorithms classify the incoming mails in various groups and, based on the comparison scores of every group with the defined set of groups, spam and non-spam emails got segregated.
This article will give an idea for implementing content-based filtering using one of the most famous algorithms for spam detection, which is K-Nearest Neighbour (KNN).
k-NN based algorithms are widely used for clustering tasks. Let’s quickly know the entire architecture of this implementation first and then explore every step. Executing these 5 steps, one after the other, will help us implement our spam classifier smoothly.
Training Testing Phase

New Email Classification

The dataset contained in a corpus plays a crucial role in assessing the performance of any spam filter. Many open-source datasets are freely available in the public domain. Below mentioned two datasets are widely popular as they contain a huge amount of emails.
Train/Test Split: Split the dataset into train and test datasets but make sure that both sets must balance numbers of ham and spam emails ( ham is a fancy name for non-spam emails).
Enron Corpus Dataset on Kaggle

At this step, we mainly perform tokenization of mails. Tokenization is a process where we break the content of an email into words and transform big messages into a sequence of representative symbols termed tokens. These tokens are extracted from the email body, header, subject, and image.
Extracting words from images (For a simple implementation, this can be ignored)These days, senders have options to attach inline images to the mail. These emails can be categorized as spam emails not based on their mail content but the images' content.
Believe me! This was not an easy task until google came up with the open-source library Tesseract. This library extracts the words from images automatically with certain accuracy. But still, Times New Roman and Captcha words are difficult to read automatically.

After pre-processing, we can have a large number of words. Here we can maintain a database that contains the frequency of the different words represented in each column. These attributes can be categorized on a different basis, like:
You must be clear that the more the number of attributes → more the time complexity of the model.
These attributes can be huge, and hence techniques like Stemming, noise removal, and stop-words removal can be used. One of the famous stemming algorithms is the Porter Stemmer Algorithm.
Some general things that we do in stemming are :
Removing of prefixes (Un-, Re-, Pre-, etc.)
List of stop words

Example dataset format

Similar to the Nearest Neighbour algorithm, the K-Nearest Neighbour algorithm serves the purpose of clustering. Still, instead of giving just one nearest instance, it looks at the closest K instances to the new incoming instance. Based on the frequency of those K instances, K-NN classifies the new instances. The value of K is considered to be a hyperparameter that needs tuning. To tune this, one can take one of the famous Hit and Trial approaches where we try some K's values and then check the model's performance.

KNN, Credit: Mathworks
To find the nearest instance, one can use the Euclidean distance. One can use the Scikit-learn library to implement the K-NN algorithm for this task.

Now our algorithm is ready, so we must check the performance of the model.
Even a single missed important message may cause a user to reconsider the value of spam filtering.
So we must be sure that our algorithm will be as close to 100% accurate. But some researchers feel that considering only the accuracy as the evaluation parameter for spam classification is not enough.
According to the below table (also known as confusion matrix), we must evaluate our spam-classification model based on 4 different parameters.

More advanced algorithms are available in the market for this classification, but you can easily achieve more than 90% accuracy using k-NN based implementation.
Google data centers use thousands of rules to filter spam emails. They provide the weightage to different parameters, and based on that; they filter the mails. Google’s spam classifier is said to be a state of an art technique that uses various techniques like Optical character recognition, linear regression, and a combination of various neural networks.
Yahoo mail is the world’s first free webmail service provider, which still has more than 320 million active users. They have their own filtering techniques to categorize the emails. Yahoo's basic methods are URL filtering, email content, and spam complaints from users. Unlike Gmail, Yahoo filter emails messages by domain and not the IP address. Yahoo provides custom filtering options to users as well to directly send the mail in the junk folders.
Microsoft-owned mailing platform widely used among professionals. In 2013, Microsoft renamed the Hotmail and Windows Live Mail to Outlook. At present, the outlook has more than 400 Million active users. Outlook has its own distinctive feature based on which it filters every incoming mail. Based on their official website, they have provided the list of spam filters they use to send any mail in the junk folder, which includes :
In terms of the number of spam emails sent daily and the number of money people lose every day because of these spam scams, Spam-filtering becomes the primary need for all email-providing companies. This article discussed the complete process of spam email filtering using advanced technologies of machine learning. We also have closed one possible way of implementing our own spam-classifier using one of the most famous algorithms, k-NN. We also discussed the case studies of famous companies like Gmail, Outlook, and Yahoo to review how they use ML and AI techniques to filter such spammers.
Question 1: What is Porter Stemmer Algorithm?
Question 2: Why k-NN algorithm for this problem?
Question 3: Is this supervised learning or unsupervised learning?
Question 4: What are the different algorithms that can replace k-NN here?
Question 5: What steps can be taken to improve accuracy further?
AlphaFold, an AI program of Google's DeepMind, solved the mystery of "How proteins fold into 3D shapes?". It was a mystery question for the past 5…

In recent days, Machine Learning is showing tremendous potential but compared to human intelligence, it is still in its earliest stage and localized…

Staring any new journey always require motivation, courage, and proper guidance. Pathway seems very neat and straight at the start, but it's always…
Subscribe to get free weekly content on DSA, Machine Learning and System Design. Content will be delivered every Monday.

{kind=link}